The publication of word2vec (as “Efficient Estimation of Word Representations in Vector Space” by Mikolov et al.) got a considerable amount of attention by demonstrating that a representation designed to predict words in context could also be used to predict analogies between words. The word2vec authors demonstrated this by including their own corpus of analogies for evaluation. Since then, other representations have been evaluated against that same corpus.
But a word representation that is better at capturing general knowledge of the relationships between things won’t necessarily do better on Mikolov et al.’s evaluation. That evaluation tests numerous examples of only a few types of analogies:
- Geographical facts, such as “Athens : Greece :: Baghdad : Iraq”
- Gender-swapping analogies, such as “man : woman :: king : queen”
- Names of international currency, such as “Angola : kwanza :: Armenia : dram”
- Morphological relationships, such as “free : freely :: happy : happily”
- Factoids about multi-word named entities, such as “Baltimore : Baltimore Sun :: Cleveland : Cleveland Plain Dealer”
The multi-word named entities are usually considered separately. Even word2vec, which this evaluation was designed to evaluate, required a differently-trained vector space to be able to get entities like “Cleveland Plain Dealer” into its vocabulary.
Conceptnet Numberbatch and analogy questions
I’ve been posting about the state-of-the-art set of word embeddings, Conceptnet Numberbatch, and you might wonder how it does on word2vec’s analogies. So even though I’m not a big fan of the word2vec analogy data, I ran a quick evaluation to find out, using Omer Levy’s 3CosMul metric for choosing the best analogies. Here’s how it scored, broken down by the type of question:
- Geography: 95.6%
- Gender: 95.8%
- Currency: 45.5%
- Morphology: ???
- Multi-word: 2.2% (most terms are out-of-vocabulary)
Let’s talk about the question marks next to “Morphology”. It doesn’t make sense to ask Numberbatch about morphology. Like most English NLP systems but unlike word2vec, Numberbatch expects morphology to be handled as a separate step. This is a better plan than forgetting everything we know about morphology and hoping the system can rediscover it.
The overwhelming majority of the morphology questions look like “write : writes :: work : works”. Notice that answering this question involves nothing about the meanings of the words “write” and “work”. In fact, the less a system knows about meaning, the less there will be to distract it from its morphological task of adding the letter “s”.
Numberbatch has the same representation for “write” and “writes”, and I think this is reasonable for a system focused on semantics. They have the same meaning, just different morphology. If you want to do morphology, ask a lemmatizer.
So Numberbatch does well on some categories, and it could probably be tuned to do better. But I think this tuning would be counterproductive, because it would reward memorized facts over general knowledge.
Teaching to the test
word2vec’s evaluation was a fine demonstration of the capabilities of word2vec when it was published, but it doesn’t make much sense as a gold standard.
I believe that a system that aces the whole evaluation could be made out of existing tools, and it wouldn’t have very much to do with semantic vectors. Given the analogy A : B :: C : D, it would just look up A and B in Wikipedia and Wiktionary, find connections between them, and return the thing that C is connected to in the same way. Using a pre-parsed version of Wikipedia and Wiktionary would help, and those are things I’ve been working with. You could add in a lemmatizer, but the best lemmatizers are basically condensed versions of Wiktionary anyway.
This would be a silly thing to make. It’s like telling a human student exactly what’s on the test, and letting them bring as many notes as they want. Nothing is left but a test of ability to look things up.
From a machine learning point of view, you might call it “training on the test set”, but I don’t think it’s quite the same thing. There’s no training step involved here. Call it “cramming for the test set” instead. The analogy evaluation is a test of whether your system knows facts and morphology, so knowing facts and morphology is how you succeed at it.
Let’s put this back in perspective, though. The reason the word2vec paper was remarkable is that word2vec wasn’t designed to know facts, or even to be able to make analogies at all. It was designed to predict words in the context of other words, and it happened to be able to make analogies. That was the cool part.
Now that we expect word vectors to be able to form analogies, let’s expect more from our analogies.
English tests for people and computers
Above, I compared a computer running an evaluation to a human learner taking a test. If you want to test whether a human understands analogies, you don’t ask them 10,000 questions about geography. You ask them a lot of different things. So I went looking for analogy tests for people.
I think these kind of analogy “equations” are falling out of favor in education, probably for good reason. They’re artificial and they have a lot to do with test-taking skills. They’re not on the SAT anymore, so if you really want to know whether a high-schooler gets analogies, now you use a separate test called the Miller Analogy Test. I think they’re still pretty reasonable for computers. Computers like equations, and they have mad test-taking skills.
Here are some simple analogies that a semantic representation should be able to make, which I found on a website of resources for English teachers:
- mouth : eat :: feet : walk
- awful : bad :: fantastic : good
- brick : wall :: page : book
- poor : money :: sad : happiness
- June : July :: Monday : Tuesday
- umbrella : rain :: sunscreen : sun
And here are some more difficult ones, from a test-prep book for the Miller Analogy Test:
- articulate : speech :: coordinated : movement
- inception : conclusion :: departure : arrival
- scintillating : dullness :: boisterous : calm
- elucidate : clarity :: illuminate : light
- shard : pottery :: splinter : wood
- attenuate : signal :: dampen : enthusiasm
These examples of analogies from tests also come with multiple-choice distractors, in contrast to the word2vec evaluation, where the vocabulary of all the questions is used as the set of distractors.
Unlike geographical facts, these questions don’t have answers that can simply be looked up. There’s no data set that would name the relationship between “articulate” and “speech” for you in such a way that you can apply the same relationship to “coordinated”. You need a system that can discover a representation of that relationship, and that’s what a good set of semantic vectors can do.
It seems that we can evaluate our semantic systems by giving them tests that were originally designed for people. This approach to semantic evaluation has been used, for example, by Peter Turney, who used SAT questions in “A Uniform Approach to Analogies, Synonyms, Antonyms, and Associations” and related publications.
And now for the big problem: people who write test questions write them under extremely restrictive terms of use. I’d better hope fair use really exists so I can even quote twelve of them here. Turney’s results can no longer be reproduced, through no fault of his, because he is not allowed to distribute his test data.
It would be great if someone who wrote test-prep questions would cooperate with the NLP community and make some of their questions available as an evaluation. I tried e-mailing the website that had the first set of questions on it. I never got a response, and I assume they’re filtering my e-mail as “Strange AI guy” now.
Making it possible to evaluate analogies
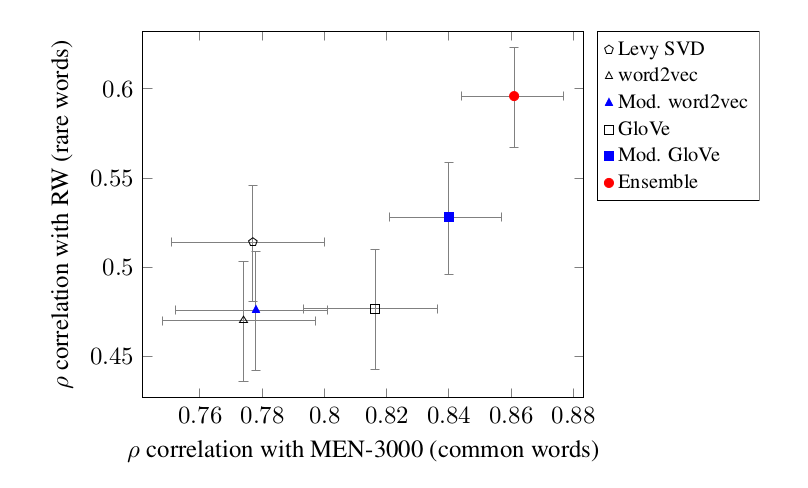
There are some great data sets out there about word similarities. MEN-3000, Rare Words, and WordSim-353 are all good examples. They’re in convenient text formats, they’re usually split into development and test sets, and they’re free to redistribute so that your experiments are reproducible.
There should be a way to get analogies up to the same standard. I’ve heard that other people who do this kind of semantics are also looking for a good analogy evaluation. We could get an evaluation corpus the traditional way, with human effort, and divide up the task of making an analogy test for computers among researchers and their students. It wouldn’t be enough for one person or one research group to write all the questions, because they would only write the kinds of questions they expect to be able to handle.
If there were a grant that could fund this, we could more straightforwardly spend money on the problem: we could buy the rights to these test-prep materials from somebody, so that we can convert them into convenient evaluation data, use them, and release them under a Creative Commons license.
Whether their preference is for neural networks, semantic graphs, or logical inferences, many schools of thought on computational semantics agree that analogies are an interesting and relevant task. We should take the opportunity to make our progress on this task measurable and reproducible by obtaining an open, sufficiently general corpus of analogies.

{kind=link}