An introduction to the ConceptNet Vector Ensemble
Here’s a big idea that’s taken hold in natural language processing: meanings are vectors. A text-understanding system can represent the approximate meaning of a word or phrase by representing it as a vector in a multi-dimensional space. Vectors that are close to each other represent similar meanings.
Vectors are how Luminoso has always represented meaning. When we started Luminoso, this was seen as a bit of a crazy idea.
It was an exciting time when the idea of vectors as meanings was suddenly popularized by the Google research project word2vec. Now this isn’t considered a crazy idea anymore, it’s considered the effective thing to do.
Luminoso’s starting point — its model of word meanings when it hasn’t seen any of your documents — comes from a vector-based representation of ConceptNet 5. That gives it general knowledge about what words mean. These vectors are then automatically adjusted based on the specific way that words are used in your domain.
But you might well ask: if these newer systems such as word2vec or GloVe are so effective, should we be using them as our starting point?

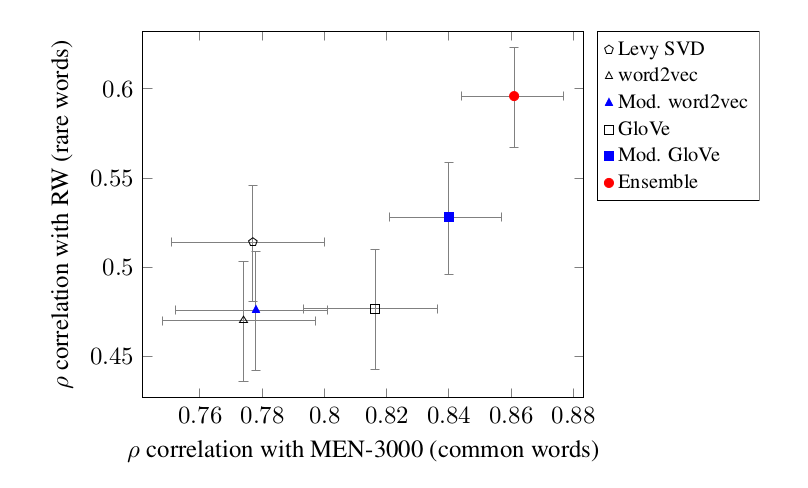
The best representation of word meanings we’ve seen — and we think it’s the best representation of word meanings anyone has seen — is our new ensemble that combines ConceptNet, GloVe, PPDB, and word2vec. It’s described in our paper, “An Ensemble Method to Produce High-Quality Word Embeddings“, and it’s reproducible using this GitHub repository.
We call this the ConceptNet Vector Ensemble. These domain-general word embeddings fill the same niche as, for example, the word2vec Google News vectors, but by several measures, they represent related meanings more like people do.
Expanding on “retrofitting”¶
Manaal Faruqui’s Retrofitting, from CMU’s Language Technologies Institute, is a very cool idea.
Every system of word vectors is going to reflect the set of data it was trained on, which means there’s probably more information from outside that data that could make it better. If you’ve got a good set of word vectors, but you wish there was more information it had taken into account — particularly a knowledge graph — you can use a fairly straightforward “retrofitting” procedure to adjust the vectors accordingly.
Starting with some vectors and adjusting them based on new information — that sure sounds like what I just described about what Luminoso does, right? Faruqui’s retrofitting is not the particular process we use inside Luminoso’s products, but the general idea is related enough to Luminoso’s proprietary process that working with it was quite natural for us, and we found that it does work well.
There’s one idea from our process that can be added to retrofitting easily: if you have information about words that weren’t in your vocabulary to start with, you should automatically expand your vector space to include them.
Faruqui describes some retrofitting combinations that work well, such as combining GloVe with WordNet. I don’t think anyone had tried doing anything like this with ConceptNet before, and it turns out to be a pretty powerful source of knowledge to add. And when you add this idea of automatically expanding the vocabulary, now you can also represent all the words and phrases in ConceptNet that weren’t in the vocabulary of your original vector space, such as words in other languages.
The multilingual knowledge in ConceptNet is particularly relevant here. Our ensemble can learn more about words based on the things they translate to in languages besides English, and it can represent those words in other languages with the same kind of vectors that it uses to represent English words.
There’s clearly more to be done to extend the full power of this representation to non-English languages. It would be better, for example, if it started with some text in other languages that it could learn from and retrofit onto, instead of relying entirely on the multilingual links in ConceptNet. But it’s promising that the Spanish vectors that our ensemble learns entirely from ConceptNet, starting from having no idea what Spanish is, perform better at word similarity than a system trained on the text of the Spanish Wikipedia.
On the other hand, you have GloVe¶
For some reason, everyone in this niche talks about word2vec and few people talk about the similar system GloVe, from Stanford NLP. We were more drawn to GloVe as something to experiment with, as we find the way it works clearer than word2vec.
When we compared word2vec and GloVe, we got better initial results from GloVe. Levy et al. report the opposite. I think what this shows is that a whole lot of the performance of these systems is in the fine details of how you use them. And indeed, when we tweak the way we use GloVe — particularly when we borrow a process from ConceptNet to normalize words to their root form — we get word similarities that are much better than word2vec and the original GloVe, even before we retrofit anything onto it.
You can probably guess the next step: “why don’t we use both?” word2vec’s most broadly useful vectors come from Google News articles, while GloVe’s come from reading the Web at large. Those represent different kinds of information. Both of them should be in the system. In the ConceptNet Vector Ensemble, we build a vector space that combines word2vec and GloVe before we start retrofitting.
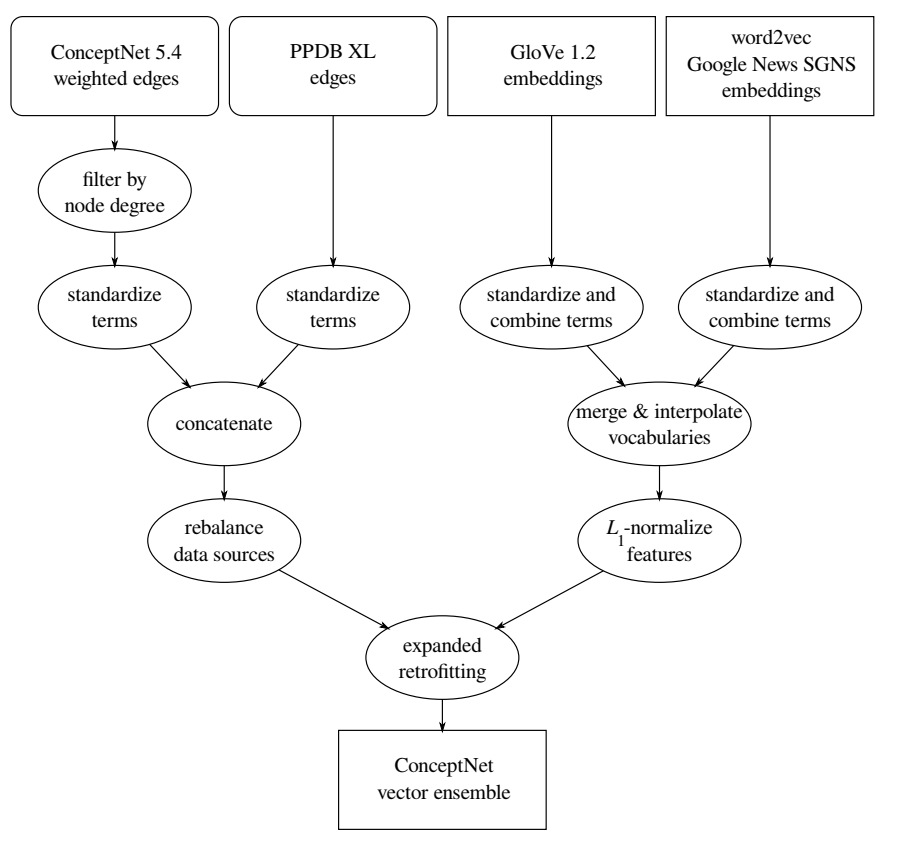
You can see that creating state-of-the-art word embeddings involves ideas from a number of different people. A few of them are our own — particularly ConceptNet 5, which is entirely developed at Luminoso these days, and the various ways we transformed word embeddings to make them work better together.
This is an exciting, fast-moving area of NLP. We’re telling everyone about our vectors because the openness of word-embedding research made them possible, and if we kept our own improvement quiet, the field would probably find a way to move on without it at the cost of some unnecessary effort.
These vectors are available for download under a Creative Commons Attribution Share-Alike license. If you’re working on an application that starts from a vector representation of words — maybe you’re working in the still-congealing field of Deep Learning methods for NLP — you should give the ConceptNet Vector Ensemble a try.
Comments
Comments powered by Disqus