Originally posted on September 1, 2015.
Often, in NLP, you need to answer the simple question: "is this a common word?" It turns out that this leaves the computer to answer a more vexing question: "What's a word?"
Let's talk briefly about why word frequencies are important. In many cases, you want to assign more significance to uncommon words. For example, a product review might contain the word "use" and the word "defective", and the word "defective" carries way more information. If you're wondering what the deal is with John Kasich, a headline that mentions "Kasich" will be much more likely to be what you're looking for than one that merely mentions "John".
For purposes like these, it would be nice if we could just import a Python package that could tell us whether one word was more common than another, in general, based on a wide variety of text. We looked for a while and couldn't find it. So we built it.
wordfreq provides estimates of the frequencies of words in many languages, loading its data from efficiently-compressed data structures so it can give you word frequencies down to 1 occurrence per million without having to access an external database. It aims to avoid being limited to a particular domain or style of text, getting its data from a variety of sources: Google Books, Wikipedia, OpenSubtitles, Twitter, and the Leeds Internet Corpus.
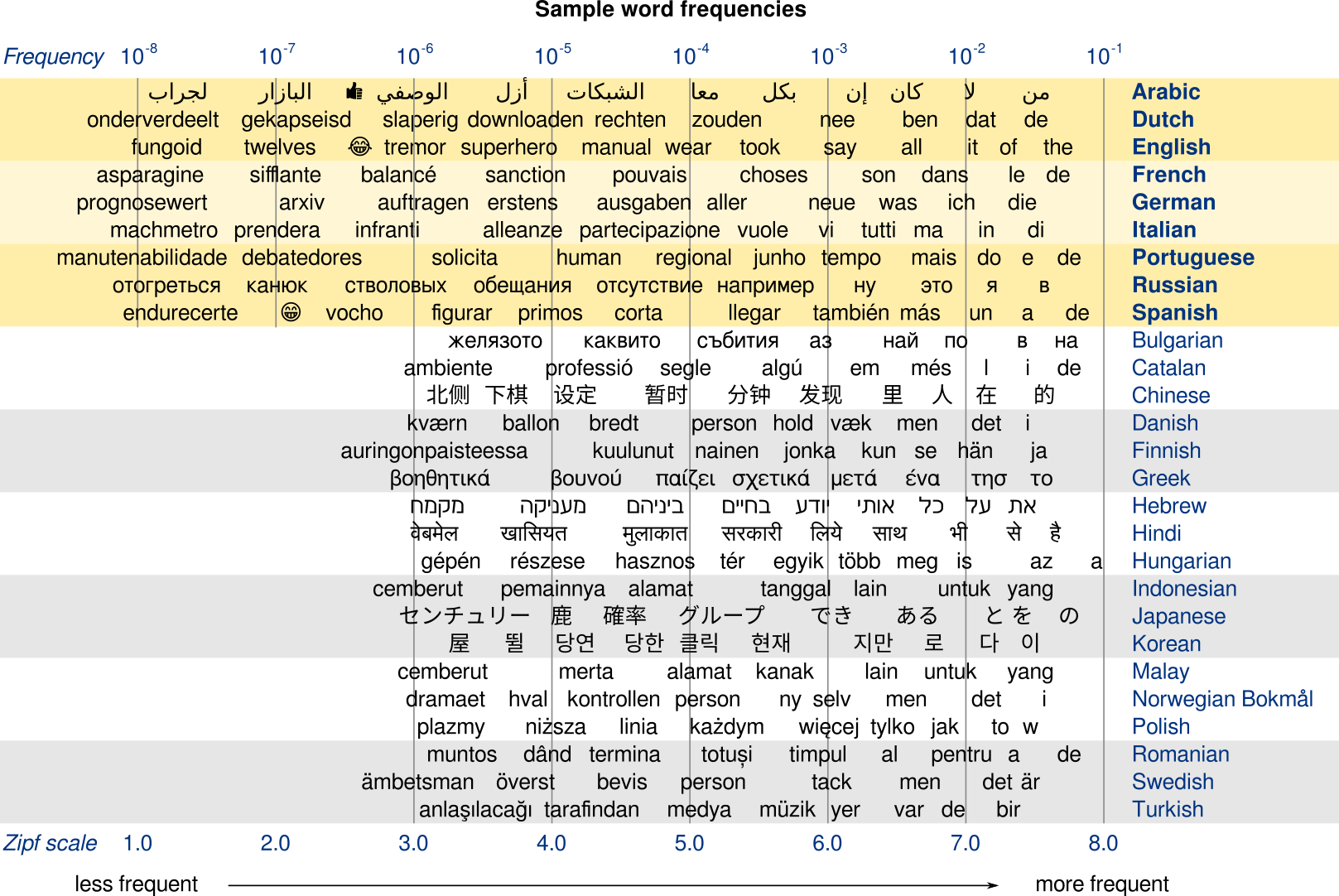
 The 10 most common words that wordfreq knows in 15 languages. Yes, it can handle multi-character words in Chinese and Japanese; those just aren't in the top 10. A puzzle for Unicode geeks: guess where the start of the Arabic list is.
The 10 most common words that wordfreq knows in 15 languages. Yes, it can handle multi-character words in Chinese and Japanese; those just aren't in the top 10. A puzzle for Unicode geeks: guess where the start of the Arabic list is.
Partial solutions: stopwords and inverse document frequency
Those who are familiar with the basics of information retrieval probably have a couple of simple suggestions in mind for dealing with word frequencies.
One is to come up with a list of stopwords, words such as "the" and "of" that are too common to use for anything. Discarding stopwords can be a useful optimization, but that's far too blunt of an operation to solve the word frequency problem in general. There's no place to draw the bright line between stopwords and non-stopwords, and in the "John Kasich" example, it's not the case that "John" should be a stopword.
Another partial solution would be to collect all the documents you're interested in, and re-scale all the words according to their inverse document frequency or IDF. This is a quantity that decreases as the proportion of documents a word appears in increases, reaching 0 for a word that appears in every document.
One problem with IDF is that it can't distinguish a word that appears in a lot of documents because it's unimportant, from a word that appears in a lot of documents because it's very important to your domain. Another, more practical problem with IDF is that you can't calculate it until you've seen all your documents, and it fluctuates a lot as you add documents. This is particularly an issue if your documents arrive in an endless stream.
We need good domain-general word frequencies, not just domain-specific word frequencies, because without the general ones, we can't determine which domain-specific word frequencies are interesting.
Avoiding biases
The counts of one resource alone tend to tell you more about that resource than about the language. If you ask Wikipedia alone, you'll find that "census", "1945", and "stub" are very common words. If you ask Google Books, you'll find that "propranolol" is supposed to be 10 times more common than "lol" overall (and also that there's something funny going on, so to speak, in the early 1800s).

If you collect data from Twitter, you'll of course find out how common "lol" is. You also might find that the ram emoji "🐏" is supposed to be extremely common, because that guy from One Direction once tweeted "We are derby super 🐏🐏🐏🐏🐏🐏🐏🐏🐏🐏🐏🐏🐏🐏🐏🐏🐏🐏🐏🐏", and apparently every fan of One Direction who knows what Derby Super Rams are retweeted it.
Yes, wordfreq considers emoji to be words. Its Twitter frequencies would hardly be complete without them.
We can't entirely avoid the biases that come from where we get our data. But if we collect data from enough different sources (not just larger sources), we can at least smooth out the biases by averaging them between the different sources.
What's a word?
You have to agree with your wordlist on the matter of what constitutes a "word", or else you'll get weird results that aren't supported by the actual data.
Do you split words at all spaces and punctuation? Which of the thousands of symbols in Unicode are punctuation? Is an apostrophe punctuation? Is it punctuation when it puts a word in single quotes? Is it punctuation in "can't", or in "l'esprit"? How many words is "U.S." or "google.com"? How many words is "お早うございます" ("good morning"), taking into account that Japanese is written without spaces? The symbol "-" probably doesn't count as a word, but does "+"? How about "☮" or "♥"?
The process of splitting text into words is called "tokenization", and everyone's got their own different way to do it, which is a bit of a problem for a word frequency list.
We tried a few ways to make a sufficiently simple tokenization function that we could use everywhere, across many languages. We ended up with our own ad-hoc rule including large sets of Unicode characters and a special case for apostrophes, and this is in fact what we used when we originally released wordfreq 1.0, which came packaged with regular expressions that look like attempts to depict the Flying Spaghetti Monster in text.

But shortly after that, I realized that the Unicode Consortium had already done something similar, and they'd probably thought about it for more than a few days.
 Word splitting in Unicode. Not pictured: how to decide which of these segments count as "words".
Word splitting in Unicode. Not pictured: how to decide which of these segments count as "words".
This standard for tokenization looked like almost exactly what we wanted, and the last thing holding me back was that implementing it efficiently in Python looked like it was going to be a huge pain. Then I found that the regex package (not the re package built into Python) contains an efficient implementation of this standard. Defining how to split text into words became a very simple regular expression... except in Chinese and Japanese, because a regular expression has no chance in a language where the separation between words is not written in any way.
So this is how wordfreq 1.1 identifies the words to count and the words to look up. Of course, there is going to be data that has been tokenized in a different way. When wordfreq gets something that looks like it should be multiple words, it will look them up separately and estimate their combined frequency, instead of just returning 0.
Language support
wordfreq supports 15 commonly-used languages, but of course some languages are better supported than others. English is quite polished, for example, while Chinese so far is just there to be better than nothing.
The reliability of each language corresponds pretty well with the number of different data sources we put together to make the wordlist. Some sources are hard to get in certain languages. Perhaps unsurprisingly, for example, not much of Twitter is in Chinese. Perhaps more surprisingly, not much of it is in German either.
The word lists that we've built for wordfreq represent the languages where we have at least two sources. I would consider the ones with two sources a bit dubious, while all the languages that have three or more sources seem to have a reasonable ranking of words.
-
5 sources: English
-
4 sources: Arabic, French, German, Italian, Portuguese, Russian, Spanish
-
3 sources: Dutch, Indonesian, Japanese, Malay
-
2 sources: Chinese, Greek, Korean
Compact wordlists
When we were still figuring this all out, we made several 0.x versions of wordfreq that required an external SQLite database with all the word frequencies, because there are millions of possible words and we had to store a different floating-point frequency for each one. That's a lot of data, and it would have been infeasible to include it all inside the Python package. (GitHub and PyPI don't like huge files.) We ended up with a situation where installing wordfreq would either need to download a huge database file, or build that file from its source data, both of which would consume a lot of time and computing resources when you're just trying to install a simple package.
As we tried different ways of shipping this data around to all the places that needed it, we finally tried another tactic: What if we just distributed less data?
Two assumptions let us greatly shrink our word lists:
- We don't care about the frequencies of words that occur less than once per million words. We can just assume all those words are equally informative.
- We don't care about, say, 2% differences in word frequency.
Now instead of storing a separate frequency for each word, we group the words into 600 possible tiers of frequency. You could call these tiers "centibels", a logarithmic unit similar to decibels, because there are 100 of them for each factor of 10 in the word frequency. Each of them represents a band of word frequencies that spans about a 2.3% difference. The data we store can then be simplified to "Here are all the words in tier #330... now here are all the words in tier #331..." and converted to frequencies when you ask for them.
 Some tiers of word frequencies in English.
Some tiers of word frequencies in English.
This let us cut down the word lists to an entirely reasonable size, so that we can put them in the repository, and just keep them in memory while you're using them. The English word list, for example, is 245 KB, or 135 KB compressed.
But it's important to note the trade-off here, that wordfreq only represents sufficiently common words. It's not suited for comparing rare words to each other. A word rarer than "amulet", "bunches", "deactivate", "groupie", "pinball", or "slipper", all of which have a frequency of about 1 per million, will not be represented in wordfreq.
Getting the package
wordfreq is available on GitHub, or it can be installed from the Python Package Index with the command pip install wordfreq. Documentation can be found in its README on GitHub.
 Comparing the frequency per million words of two spellings of "café", in English and French.
Comparing the frequency per million words of two spellings of "café", in English and French.
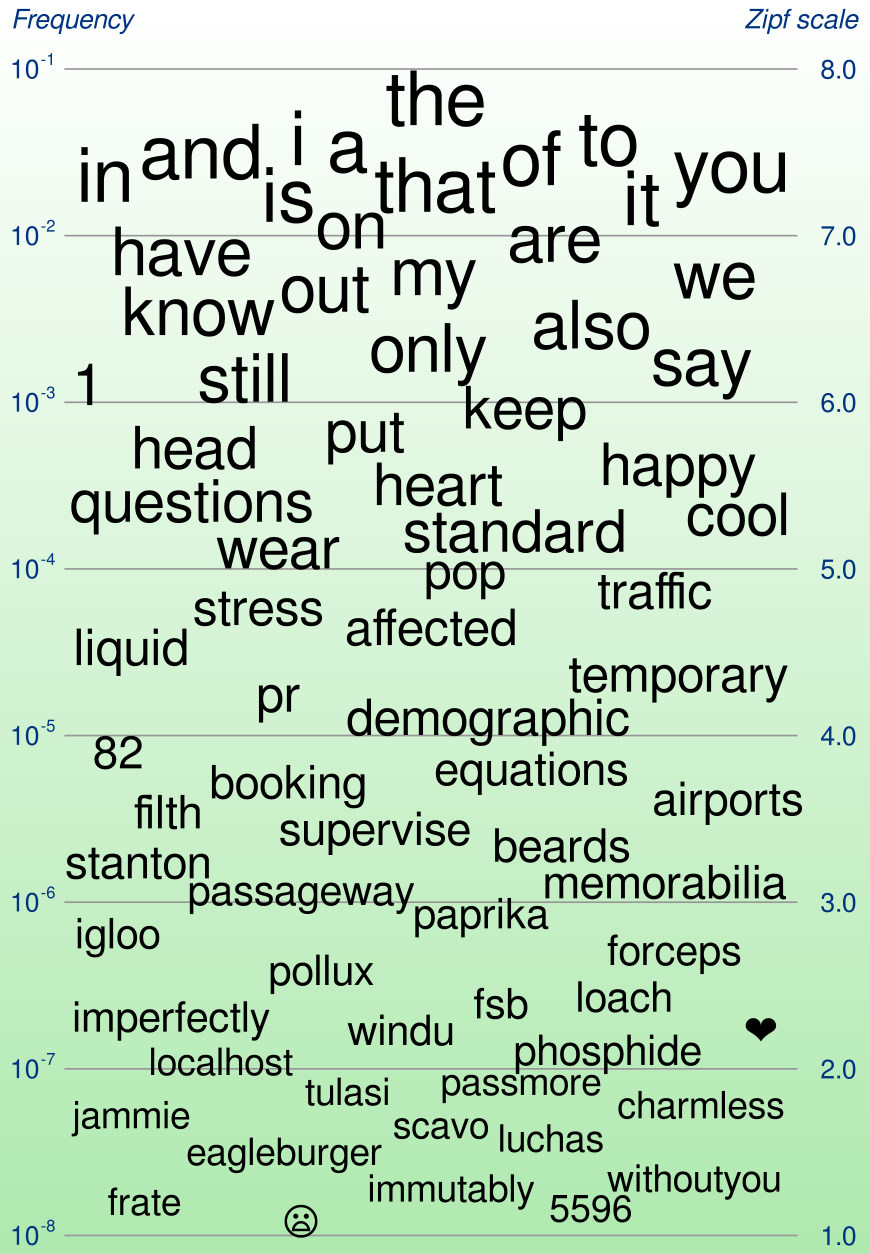 wordfreq can rank the frequencies of nearly 400,000 English words. These are some of them.
wordfreq can rank the frequencies of nearly 400,000 English words. These are some of them.