Announcing ConceptNet 5.5 and conceptnet.io
ConceptNet is a large, multilingual knowledge graph about what words mean.
This is background knowledge that's very important in NLP and machine learning, and it remains relevant in a time when the typical thing to do is to shove a terabyte or so of text through a neural net. We've shown that ConceptNet provides information for word embeddings that isn't captured by purely distributional techniques like word2vec.
At Luminoso, we make software for domain-specific text understanding. We use ConceptNet to provide a base layer of general understanding, so that our machine learning can focus on quickly learning what's interesting about text in your domain, when other techniques have to re-learn how the entire language works.
ConceptNet 5.5 is out now, with features that are particularly designed for improving word embeddings and for linking ConceptNet to other knowledge sources.
The new conceptnet.io
With the release of ConceptNet 5.5, we've relaunched its website at conceptnet.io to provide a modern, easy-to-browse view of the data in ConceptNet.
The old site was at conceptnet5.media.mit.edu, and I applaud the MIT Media Lab sysadmins for the fact that it keeps running and we've even been able to update it with new data. But none of us are at MIT anymore -- we all work at Luminoso now, and it's time for ConceptNet to make the move with us.
ConceptNet improves word embeddings
Word embeddings represent the semantics of a word or phrase as many-dimensional vectors, which are pre-computed by a neural net or some other machine learning algorithm. This is a pretty useful idea. We've been doing it with ConceptNet since before the term "word embeddings" was common.
When most developers need word embeddings, the first and possibly only place they look is word2vec, a neural net algorithm from Google that computes word embeddings from distributional semantics. That is, it learns to predict words in a sentence from the other words around them, and the embeddings are the representation of words that make the best predictions. But even after terabytes of text, there are aspects of word meanings that you just won't learn from distributional semantics alone.
To pick one example, word2vec seems to think that because the terms "Red Sox" and "Yankees" appear in similar sentences, they mean basically the same thing. Not here in Boston, they don't. Same deal with "high school" and "elementary school". We get a lot of information from the surrounding words, which is the key idea of distributional semantics, but we need more than that.
When we take good word embeddings and add ConceptNet to them, the results are state-of-the-art on several standard evaluations of word embeddings, even outperforming recently-released systems such as FastText.
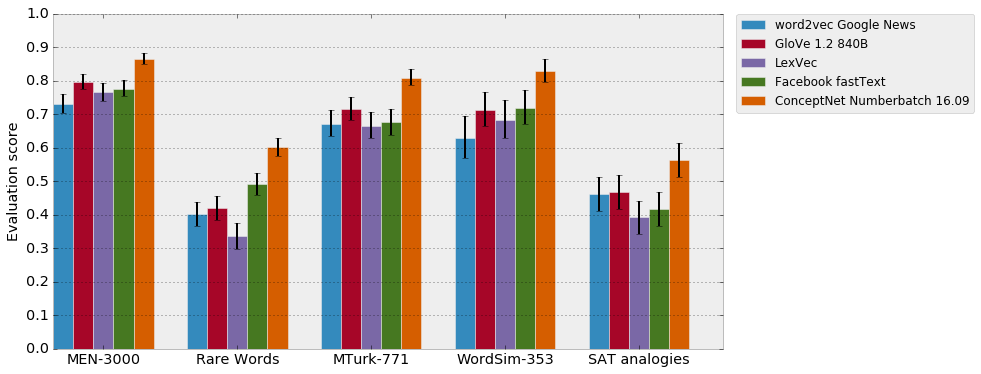 Comparing the performance of available word-embedding systems. Scores are measured by Spearman correlation with the gold standard, or (for SAT analogies) by the proportion of correct answers. The orange bar is the embeddings used in ConceptNet 5.5.
Comparing the performance of available word-embedding systems. Scores are measured by Spearman correlation with the gold standard, or (for SAT analogies) by the proportion of correct answers. The orange bar is the embeddings used in ConceptNet 5.5.
We could achieve results like this with ConceptNet 5.4 as well, but 5.5 has a big change in its representation that makes it a better match for word embeddings. In previous versions, English words were all reduced to a root form before they were even represented as a ConceptNet node. There was a node for "write", and no node for "wrote"; a node for "dog", and no node for "dogs". If you had a word in its inflected form, you had to reduce it to a root form (using the same algorithm as ConceptNet) to get results. That helped for making the data more strongly-connected, but made it hard to use ConceptNet with other things.
This stemming trick only ever applied to English, incidentally. We never had a consistent way to apply it to all languages. We didn't even really have a consistent way to apply it to English; any stemmer is either going to have to take into account the context of a sentence (which ConceptNet nodes don't have) or be wrong some of the time. (Is "saw" a tool or the past tense of "see"?) The ambiguity and complexity just become unmanageable when other languages are in the mix.
So in ConceptNet 5.5, we've changed the representation of word forms. There are separate nodes for "dog" and "dogs", but they're connected by the "FormOf" relation, and we make sure they end up with very similar word vectors. This will make some use cases easier and others harder, but it corrects a long-standing glitch in ConceptNet's representation, and incidentally makes it easier to directly compare ConceptNet 5.5 with other systems such as word2vec.
Solving analogies like a college applicant
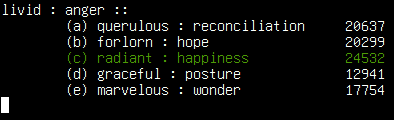 ConceptNet picks the right answer to an SAT question.
ConceptNet picks the right answer to an SAT question.
One way to demonstrate that your word-embedding system has a good representation of meaning is to use it to solve word analogies. The usual example, pretty much a cliché by now, is "man : woman :: king : queen". You want those word vectors to form something like a parallelogram in your vector space, indicating that the relationships between these words are parallel to each other, even if the system can't explain in words what the relationship is. (And I really wish it could.)
In an earlier post, Cramming for the Test Set, I lamented that the Google analogy data that everyone's been using to evaluate their word embeddings recently is unrepresentative, and it's a step down in quality from what Peter Turney has been using in his analogy research since 2005. I did not succeed in finding a way to open up some good analogy data under a Creative Commons license, but I did at least contact Turney to get his data set of SAT questions.
The ConceptNet Numberbatch word embeddings, built into ConceptNet 5.5, solve these SAT analogies better than any previous system. It gets 56.4% of the questions correct. The best comparable previous system, Turney's SuperSim (2013), got 54.8%. And we're getting ever closer to "human-level" performance on SAT analogies -- while particularly smart humans can of course get a lot more questions right, the average college applicant gets 57.0%.
We can aspire to more than being comparable to a mediocre high school student, but that's pretty good for an AI so far!
The Semantic Web: where is it now?
By now, the words "Semantic Web" probably either make you feel sad, angry, or bored. There were a lot of promises about how all we needed to do was get everyone to put some RDF and OWL in their XML or whatever, and computers would get smarter. But few people wanted to actually do this, and it didn't actually accomplish much when they did.
But there is a core idea of the Semantic Web that succeeded. We just don't call it the Semantic Web anymore: we call it Linked Data. It's the idea of sharing data, with URLs, that can explain what it means and how to connect it to other data. It's the reason Gmail knows that you have a plane flight coming up and can locate your boarding pass. It's the reason that editions of Wikipedia in hundreds of languages can be maintained and updated. I hear it also makes databases of medical research more interoperable, though I don't actually know anything about that. Given that there's this shard of the Semantic Web that does work, how about we get more semantics in it by making sure it works well with ConceptNet?
The new conceptnet.io makes it easier to use ConceptNet as Linked Data. You can get results from its API in JSON-LD format, a new format for sharing data that blows up some ugly old technologies like RDF+XML and SPARQL, and replaces them with things people actually want to use, like JSON and REST. You can get familiar with the API by just looking at it in your Web browser -- when you're in a browser, we do a few things to make it easy to explore, like adding hyperlinks and syntax highlighting.
When I learned about JSON-LD, I noticed that it would be easy to switch ConceptNet to it, because the API looked kind of like it already. But what really convinced me to make the switch was a strongly-worded rant by W3C member Manu Sporny, which both fans and foes of Semantic Web technologies should find interesting, called "JSON-LD and Why I Hate the Semantic Web". A key quote:
If you want to make the Semantic Web a reality, stop making the case for it and spend your time doing something more useful, like actually making machines smarter or helping people publish data in a way that’s useful to them.
Sounds like a good plan to me. We've shown a couple of ways that ConceptNet is making machines smarter than they could be without it, and some applications should be able to benefit even more by linking ConceptNet to other knowledge bases such as Wikidata.
Find out more
ConceptNet 5.5 can be found on the Web and on GitHub.
The ConceptNet documentation has been updated for ConceptNet 5.5, including an FAQ.
If you have questions or want more information, you can visit our new chat room on Gitter.
Comments