 There are many articles you could read for background on the problem, including:
There are many articles you could read for background on the problem, including:
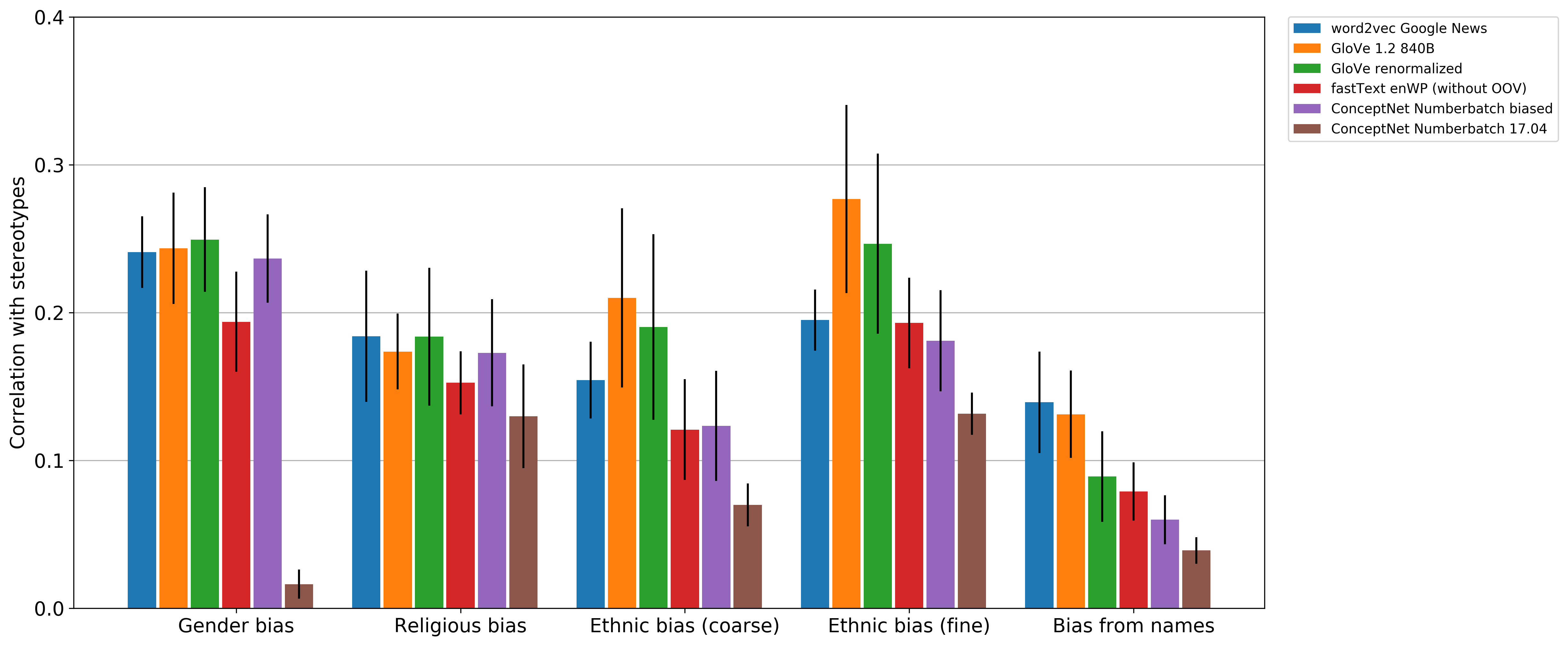 We're not trying to say we've solved the problem, but we can conclude that we've made the problem smaller. Keep in mind that this evaluation itself will likely change in the future, as we gain a better understanding of how to measure bias.
In dealing with machine-learning bias, there's the concern that removing the bias could also cause changes that remove accuracy. But we've found that the change is negligible: about 1% of the overall result, much smaller than the error bars. Here's the updated evaluation graph. The y-axis is the Spearman correlation with gold standard data (higher is better). The evaluations here are for English words only -- Numberbatch covers many more languages, but the systems we're comparing to don't.
We're not trying to say we've solved the problem, but we can conclude that we've made the problem smaller. Keep in mind that this evaluation itself will likely change in the future, as we gain a better understanding of how to measure bias.
In dealing with machine-learning bias, there's the concern that removing the bias could also cause changes that remove accuracy. But we've found that the change is negligible: about 1% of the overall result, much smaller than the error bars. Here's the updated evaluation graph. The y-axis is the Spearman correlation with gold standard data (higher is better). The evaluations here are for English words only -- Numberbatch covers many more languages, but the systems we're comparing to don't.
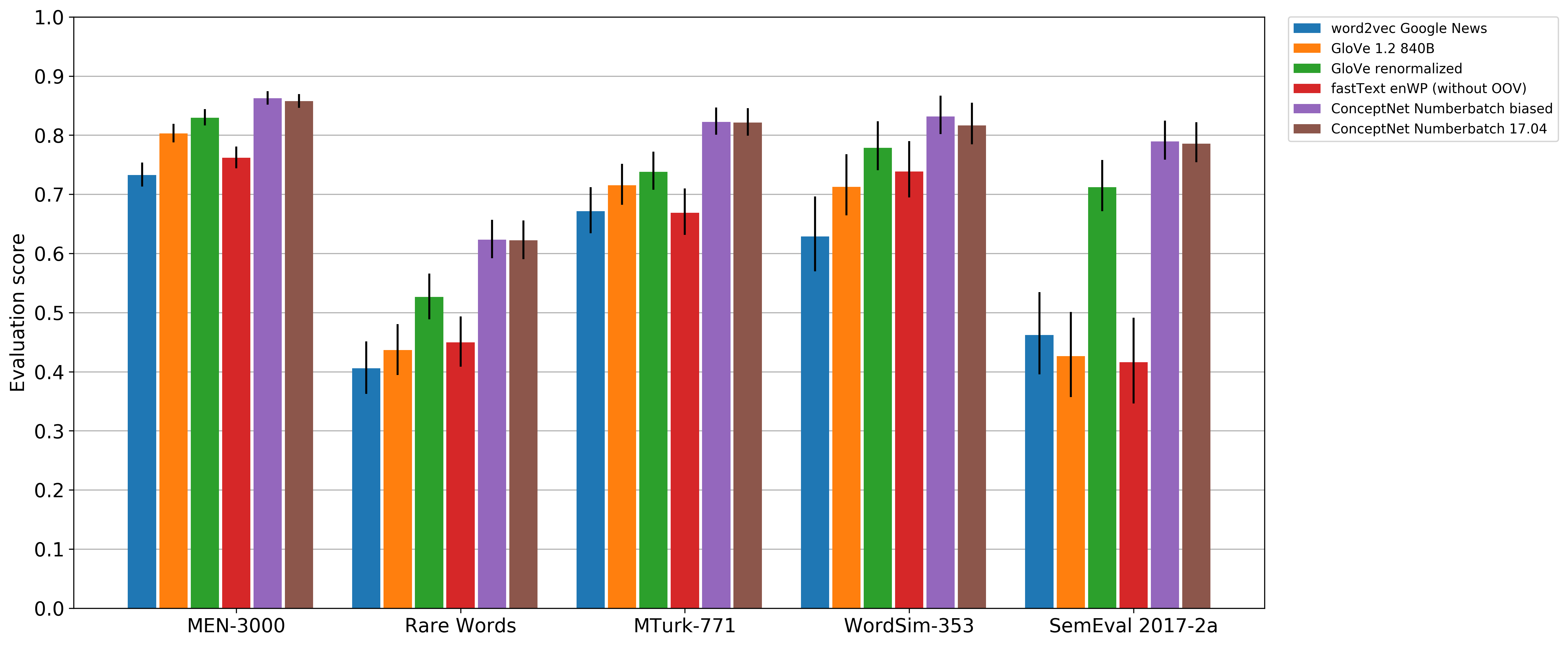 ConceptNet Numberbatch is already so much more accurate than any other released system that it can lose 1% of its accuracy for a good cause. If you want 1% more accuracy out of your word vectors, I suggest focusing on improving a knowledge graph, not putting back the stereotypes.
ConceptNet Numberbatch is already so much more accurate than any other released system that it can lose 1% of its accuracy for a good cause. If you want 1% more accuracy out of your word vectors, I suggest focusing on improving a knowledge graph, not putting back the stereotypes.
woman - man ≈ queen - king
This is remarkably similar to the way that analogies are presented in, for example, an English class, or a standardized test such as the Miller Analogies Test or former SAT tests:woman : man :: queen : king
Evaluating analogies like these led researchers to wonder what other analogies could be created in this system by adding “woman” and subtracting “man” to a word, or vice versa. And some of the results revealed a problem. In the following examples, the word2vec system was given the first three words of an analogy, and asked for the word in its vocabulary that best completed the equation. The results revealed gender biases that had been baked into the system:man : woman :: shopkeeper : housewife
man : woman :: carpentry : sewing
man : woman :: pharmaceuticals : cosmetics
I wonder if the excessive focus on Mikolov et al.'s analogy evaluation has exacerbated the problem. When a system is asked repeatedly to make analogies of the form male word : female word :: other male word : other female word, and it's evaluated on this and its knowledge of geography and not much else, is it any surprise that we end up with systems that amplify stereotypes that distinguish women and men?
The problem is not just a theoretical problem that shows up when playing with analogies. Word embeddings are actively used in many different fields of natural language processing. A system that searches résumés for people with particular programming skills could end up ranking women lower: the phrase “she developed software for…” would be a worse match for the classifier’s expectations than “he developed software for…”. This is one of the biases that we strive to remove, and the one we are most successful at removing, as described later in this post.If a restaurant were described as doing something “illegal”, that would be a pretty negative statement about the restaurant, right? But the Web contains lots of text where people use the word “Mexican” disproportionately along with the word “illegal”, particularly to associate “Mexican immigrants” with “illegal immigrants”. The system ends up learning that “Mexican” means something similar to “illegal”, and so it must mean something bad.
The tests I implemented for ethnic bias are to take a list of words, such as "white", "black", "Asian", and "Hispanic", and find which one has the strongest correlation with each of a list of positive and negative words, such as "cheap", "criminal", "elegant", and "genius". I did this again with a fine-grained version that lists hundreds of words for ethnicities and nationalities, and thus is more difficult to get a low score on, and again with what may be the trickiest test of all, comparing words for different religions and spiritual beliefs.
In these tests, for each positive and negative word, I find the group-of-people word that it's most strongly associated with, and compare that to the average. The difference is the bias for that word, and in the end it's averaged over all the positive and negative words. This appears in the graphs as "Ethnic bias (coarse)", "Ethnic bias (fine)", and "Religious bias".
Note that it's infeasible to reach 0 on this scale -- words for groups of people will necessarily have some different associations. Even random differences between the words would give non-zero results. This is one reason I don't consider the scale to be final. I'd like to make one that works like the gender-bias scale, where reaching 0 is attainable and desirable.
The Science article uncovers racial biases in a different way: it looks for different associations with predominantly-black names, such as "Deion", "Jamel", "Shereen", and "Latisha", versus predominantly-white names, such as "Amanda", "Courtney", "Adam", and "Harry". I incorporated a version of this (and also added some predominantly Hispanic and Islamic names) as another test, shown on the graph as "Bias from names".
In ConceptNet Numberbatch, we've extended Bolukbasi's de-biasing method to cover multiple types of prejudices, including ethnic and religious. This, too, is discussed below in the "What we've done" section.
A system that reads the text of pages sampled from the Web is going to read a lot of the text of porn pages. As such, it is going to end up learning associations for many kinds of words, such as “girlfriend”, “teen”, and “Asian”, that would be very inappropriate to put into production in a machine learning system.
Many of these associated terms, such as “slut”, are negative in connotation. This causes gender bias, ethnic bias, and more. When countering all of these biases, we need to make sure that people are not associated with degrading terminology because of their gender, ethnicity, age, or sexual orientation. This is another aspect of words that we strive to de-bias.
What I call “Google-style” de-biasing is described in a post on the Google Research Blog, “Equality of Opportunity in Machine Learning”. In this view, the data is what it is; if the data is unfair, it’s a reflection of the world being unfair. So the goal is to identify the point at which a machine learning tool makes a decision that affects someone (their example is a classifier that decides whether to grant a loan), and de-bias the actual decision that it makes, providing equal opportunity regardless of what the system learned from its data.
They caution against “fairness through unawareness”, the attempt to produce a system that’s unbiased just because it’s not told about attributes such as gender or race, because machine learning is great at picking up on correlated patterns that could be a proxy for gender or race.
Google’s approach is a principled and reasonable approach to take, especially in a workplace that venerates data above all else. But it sounds like it involves a large and never-ending amount of programmer effort to ensure that biased data leads to unbiased decisions. I have to wonder how many of Google’s products that use machine learning really have a working “equal opportunity filter” on their output.
In the “Microsoft-style” approach, when your data is biased against some group of people, you change the data until it’s more fair, which should help to de-bias anything you do with that data. This approach avoids “unawareness” because it adjusts all the data that’s correlated with the identified bias. I call this “Microsoft-style” because it’s based on the Microsoft Research paper (Bolukbasi et al.) that I linked to.
To remove a gender bias from word embeddings, for example, you can collect many examples of word pairs that are gender-biased and shouldn’t be (such as “doctor” vs. “nurse”), and use them to find the combination of word-embedding components that are responsible for gender bias. Then you mathematically adjust the components so that that combination comes out to 0.
It’s not quite that simple -- doing exactly what I said could result in a system that’s unbiased because it has no idea what gender is, which would harm its ability to understand words that carry actual information about gender (such as “she” or “uncle”). You need to also have examples of words that are appropriate to distinguish by gender, such as “he” and “she”, or “aunt” and “uncle”. You then train the system to find the right balance between destroying biased assumptions and preserving useful information about gender.
To summarize the effects of these approaches, I would say that Microsoft-style de-biasing is more transferable between different tasks, but Google-style lets you positively demonstrate that certain things about your system are fair, if you use it consistently. If you control your machine learning pipeline from end to end, from source data to the point where you make a decision, I would say you should do both.
 And here's what the graph looks like after de-biasing. The inappropriate gender distinctions have been set to nearly zero.
And here's what the graph looks like after de-biasing. The inappropriate gender distinctions have been set to nearly zero.
 We use similar steps to remove biased associations with different races, ethnicities, and religions. Because we don't have nice crowd-sourced data for exactly what should be removed in those cases, we instead aim to de-correlate them with words representing positive and negative sentiment.
We hope we're pushing word vectors away from biases and prejudices, and toward systems that don't think of you any differently whether you're named Stephanie or Shanice or Santiago or Syed.
We use similar steps to remove biased associations with different races, ethnicities, and religions. Because we don't have nice crowd-sourced data for exactly what should be removed in those cases, we instead aim to de-correlate them with words representing positive and negative sentiment.
We hope we're pushing word vectors away from biases and prejudices, and toward systems that don't think of you any differently whether you're named Stephanie or Shanice or Santiago or Syed.